Uitleg GAN
Wat is een GAN?
GAN staat voor Generative Adversarial Network. Een GAN is een generatief model, waar twee neurale netwerken met elkaar concurreren.
Het eerste netwerk is de generator, die een sample genereert. De tegenstander, ook wel de discriminator, probeert te detecteren of de gegenereerde sample echt of nep is.
Wat is een neuraal netwerk?
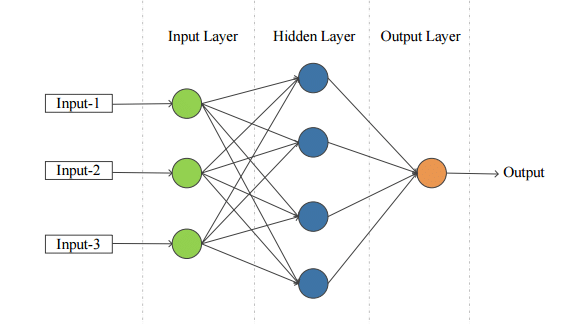
Een neuraal netwerk is een reeks van algoritmes dat als input een set van data krijgt en probeert de onderliggende relaties te vinden in die sets van data. Het proces hiervan lijkt een beetje op het proces van het menselijk brein.
Een voorbeeld van een neuraal netwerk is hieronder te zien in de afbeelding. Een neuraal netwerk bestaat minstens uit een input layer en een output layer. Daarnaast kunnen er nog hidden layers toegevoegd worden.
Generator
De rol van de generator zal uiteindelijk zijn om de afbeeling te genereren die de gebruiker wilt zien. Daar zit echter een proces achter die ervoor zorgt dat de generator dit kan doen.
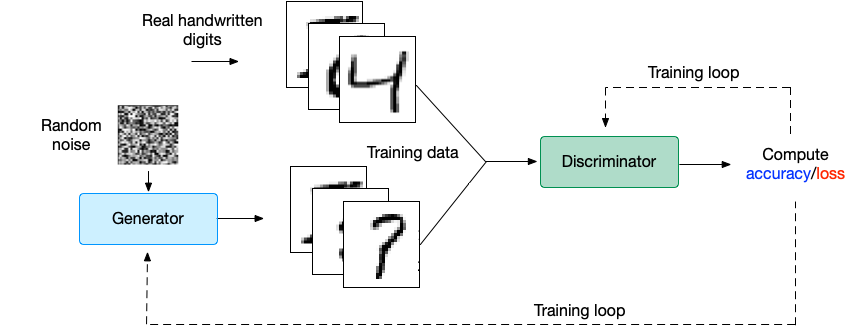
In het figuur hieronder is dit hele proces te zien. De generator die begint met het genereren van een afbeelding dat alleen maar ruis is. Hierna stuurt de generator deze afbeelding naar de discriminator.
De rol van de generator is om input te creëren, waarvan de discriminator denkt dat die thuishoort in de oorspronkelijke dataset. De generator liegt als het ware tegen de discriminator door nieuwe input te maken die niet in de dataset hoort, maar die wel aan de criteria voldoet.
Discriminator
De rol van de discriminator is om de afbeelding van de generator te verwerken en te kijken of deze real of fake is.
In onderstaand figuur is dit ook te zien. De discriminator die krijgt een dataset binnen met afbeeldingen die real zijn. Aan de hand van deze afbeelding moet de discriminator gaan beslissen of de afbeelding van de generator real of fake is.
Op de foto is ook te zien dat er een accuracy/loss is. Dit zijn de waardes die zowel de discriminator als de generator gebruikt om zichzelf constant te verbeteren.
De twee neurale netwerken (discriminator en generator) spelen dus als het ware een spel tegen elkaar, en werken tevens ook tegelijkertijd.
GAN Applicaties
GAN's zijn nog een nieuw concept waarmee met de dag steeds meer en meer applicaties gemaakt worden. De eerste GAN die is namelijk in Juni 2014 gemaakt. In de 7 jaren zijn er al grote stappen gemaakt in de dit onderwerpen. Hier zijn er een aantal die mogelijk gemaakt zijn met GAN's:
Foto's
In het opzicht van foto's zijn GAN's behulpzaam geworden met het bijvoorbeeld verbeteren van foto's. Een voorbeeld hiervan is de ExGAN. Hiermee kan de GAN bijvoorbeeld een foto genereren van iemand die zijn ogen open heeft van een foto waar iemand zijn ogen dicht had.
In onderstaand figuur is dit terug te zien. Hierop is de linkerfoto de reference die ze gebruiken voor het openen van de ogen, de 2de reeks van foto's het originele foto. In de 3de reeks zie je hoe de reference bij het origineel erbij gedaan wordt en de 4e reeks van foto's is het resultaat.

Daarnaast zijn er nog twee applicaties van foto's in de laatste paar jaren eruitgekomen die vrij populair zijn, namelijk deepfakes en faceswaps. Deepfakes en faceswaps zijn de laatste paar jaren grote rages geweest. Beide rages zijn mogelijk gemaakt door GAN's.
Kunst
De Mona Lisa is een schilderij dat vrijwel iedereen wel kent. Tegenwoordig is het mogelijk gemaakt om, door middel van de manier hoe ook deepfakes gemaakt worden, gelaatsuitdrukkingen te weergeven op het portret. Hieronder is een gif te zien waarop je gelaatsuitdrukkingen kunt zien van de Mona Lisa.

De Mona Lisa is een van de voorbeelden waarmee dat gedaan is. Een ander voorbeeld is nog Albert Einstein, maar het kan in principe nu met elk portret met een gezicht gedaan worden.
Een ander voorbeeld van GAN's in de kunstcategorie is letterlijk het maken van portretten. Een kunstenaar genaamd Mario Klingemann heeft portretten gemaakt door middel van GAN's
Pizza!
Er is een GAN genaamd PizzaGAN die kan vertellen, aan de hand van een foto, welke toppings er op die pizza zitten en op welke volgorde deze gezet moeten worden.
Daarnaast is het ook mogelijk om met deze GAN een pizza te maken. Door toppings toe te voegen of te verwijderen, maar ook door de pizza te bakken of "onbakken", kan deze GAN een pizza genereren! Voorbeeld hiervan is te zien in onderstaand figuren.


GAN Types
Bij het vorig onderdeel zijn er voorbeelden gegeven van GAN applicaties. In dit onderdeel gaan we het hebben over een aantal types van GAN.
Genereren van voorbeelden van datasets met afbeeldingen
Dit type GAN krijgt een dataset als training binnen en genereert een afbeelding dat lijkt op een afbeeldingen wat afkomstig zou kunnen zijn uit die dataset. Voorbeeld hierbij is de MNIST dataset. De GAN krijgt die dataset binnen en moet dan een afbeelding genereren dat moet lijken op een handgeschreven cijfer.
Foto Editing
Foto editing is een type GAN dat een foto als input krijgt en die aanpast met bijvoorbeeld het veranderen van haar, glimlach of de ogen. De ExGAN is hier een voorbeeld van.
Text-to-Image translation
Text-to-Image translation is een type GAN dat als input een woord of een zin krijgt en de GAN moet dan een afbeelding genereren wat er in die zin staat. Een voorbeeld hiervan is hieronder in het figuur te zien. De zin "this bird is a red with white and has a very short beak" is vertaald in de afbeelding die daaronder te zien is.

GAN architecturen
DCGAN
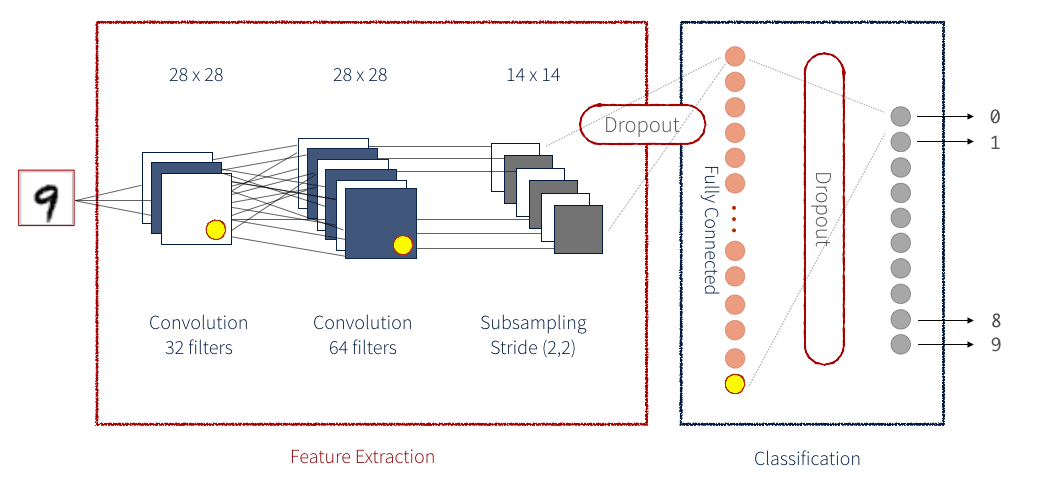
Een Deep Convolutional Neural Network (DCGAN) dat net als de normale GAN gebruikt maakt van een discriminator en een generator, maar de netwerken die hierbij gebruikt worden zijn Convolutional Neural Networks (CNN). Hierbij wordt er gebruik gemaakt van zogenaamde filters. Deze zorgen ervoor dat de prestaties van de training beter worden, maar de tijd van de training duurt aanzienelijk langer dan bij een normaal neuraal netwerk. Hieronder is een voorbeeld te zien van een CNN. In de feature extraction zie je als eerste de input layer en daarna 2 hidden layers. De classification is de output layer. Die moet beslissen welk cijfer het is.
cGAN
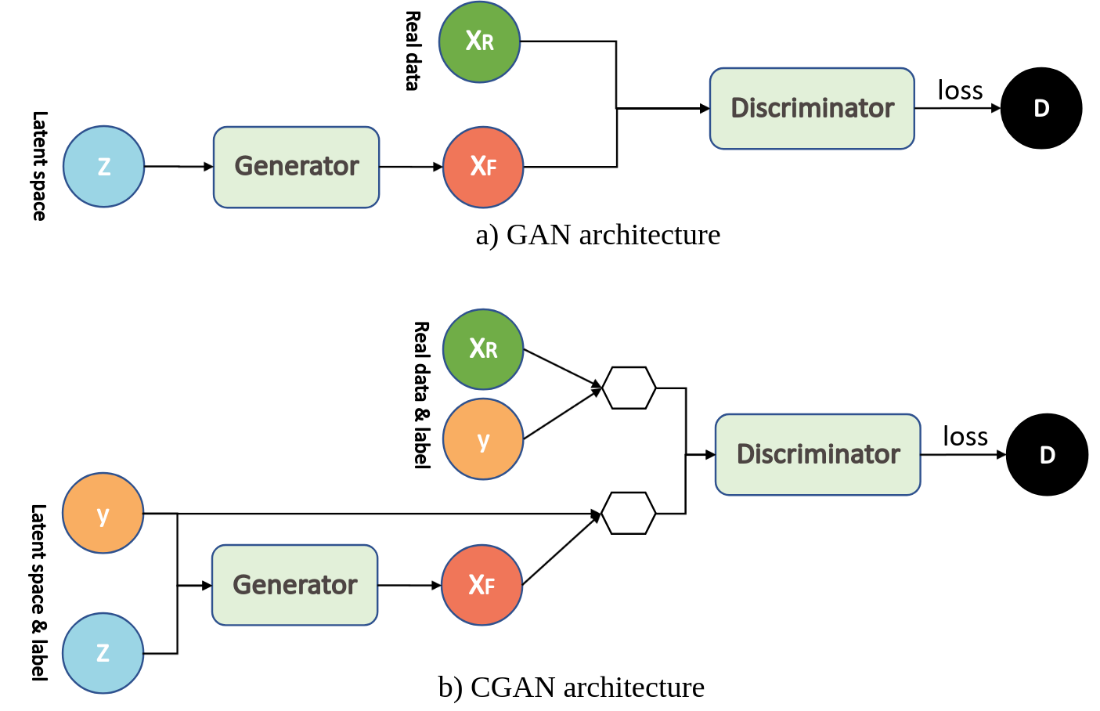
Een cGAN architectuur lijkt veel op GAN en DCGAN. Het grote verschil tussen cGAN en de andere twee is dat er een extra input bijkomt, namelijk labels. Normaal heeft een gegenereerde afbeelding geen label. Dit komt doordat deze niet als input wordt meegegeven en in de training ook niet gebruikt wordt. Bij een cGAN is dit wel het geval. Hierbij is er voor zowel de generator als de discriminator een extra input bijgekomen, namelijk de label. Dit verschil tussen DCGAN en CGAN is ook terug te zien in onderstaand figuur.
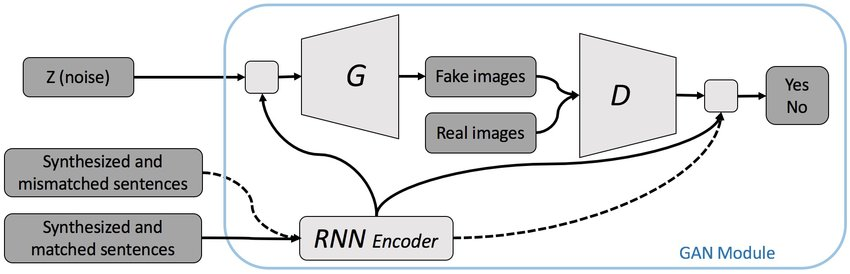
GAN-CLS
GAN-CLS is een architectuur dat gebruikt wordt voor text-to-image translation. Een DCGAN architectuur kan ook gebruikt worden voor text-to-image. Hierbij krijgt het dan een zin en ruis als input en de discriminator heeft dan twee keuzes: De afbeelding en tekst zijn fout of de afbeelding en tekst zijn goed. GAN-CLS gaat hier nog een stap verder mee. De discriminator krijgt namelijk een derde keuze erbij, namelijk: De afbeelding is goed, maar de bijbehorende tekst is niet correct. Dit concept is ook terug te vinden in onderstaand figuur.
DCGAN met MNIST dataset
Hierboven is uitgelegd hoe een GAN werkt. Bij het voorbeeld is een dataset gebruikt genaamd de MNIST dataset. Dit is een dataset die gevuld is met zelfgeschreven cijfers en bestaat uit 70000 verschillende handgeschreven cijfers. De MNIST dataset is een populaire dataset om te gebruiken voor neurale netwerken. Dit komt doordat de dataset makkelijk op te halen is en een goede hoeveelheid afbeeldingen heeft. Daarnaast zijn de afbeeldingen niet complex en ze zijn zwart/wit. Dit allemaal zorgt ervoor dat de training niet al te lang duurt.
Voor dit project is er begonnen met het maken van een DCGAN die cijfers kan genereren. De reden hiervoor is dat het concept van GAN nog niet bekend was aan het begin van dit project. Hierdoor hebben we voor een DCGAN gebruikt, doordat deze in architectuur hetzelfde is als een normale GAN maar beter met afbeeldingen, en de MNIST dataset door de voordelen van deze dataset.

Eindresultaat
Voor het eindproduct is er gekozen voor een simpele vorm van text-to-image translation. Hierbij is er gekozen voor een cGAN architectuur en de dataset is de MNIST dataset. De reden hiervoor is dat een belangrijk aspect in dit project voor ons was interactiviteit. Er kon gekozen worden voor het genereren van een afbeelding van een dataset, maar dan is er alleen een afbeelding te zien waarvan mensen maar moeten geloven dat dit gegenereerd is. De keuze van de dataset komt doordat er zoveel voordelen hangen aan deze dataset. Doordat we de MNIST dataset hebben gebruikt, is er gekozen voor een cGAN architectuur. Dit komt doordat we labels nodig hebben bij de afbeeldingen om aan te geven wat de gegeneerde afbeelding moet weergeven.
In de tab Demonstrator kan hier getest worden met dit eindresultaat.